Conversando na cozinha durante um lanche, a mãe da minha namorada me falou que ela e o marido tiveram um problema com advogado a um tempo. Se não bastasse ter problema com a empresa, o advogado responsável também não foi fácil.
Eu falei para ela que da pra ver o processo na internet, é só saber onde foi e procurar pelo nome. A um tempo atrás encontrei um processo de um conhecido em um tribunal do Maranhão apenas procurando o nome dele. Como sou um garoto prestativo, depois do lanche fui dar uma olhada nisso.
No site do tribunal regional do trabalho de Curitiba não foi possível procurar pelo nome dela ou do marido. Só era possível procurar pelo número do processo, nome do advogado, entre outros. Eu tinha o primeiro nome do Advogado, vou chamá-lo de E4r. Enquanto a mãe da minha namorada procurava o cartão dele fiz uma busca no Google: “E4r trabalhista Curitiba”. Achei o nome completo do advogado.
Com o nome completo fiz a busca no site do tribunal pelo nome do advogado: mais ou menos 3600 resultados =/
Pense num cara com processo, acho que tinha uns lá de 1980 e poucos. Depois percebi que o nome do reclamante (não sei se esse é o termo) vem como autor do processo na listagem. Ainda dei uma olhada rápida de traz para frente (o processo era de 1994-95 segundo minha namorada) mas sinceramente, nesse caso para encontrar o processo, a pessoa tinha que ser um pouco mais minuciosa e paciente do que eu sou. Pensei em deixar o trabalho braçal pra minha namorada mas
lembrei desse gráfico: 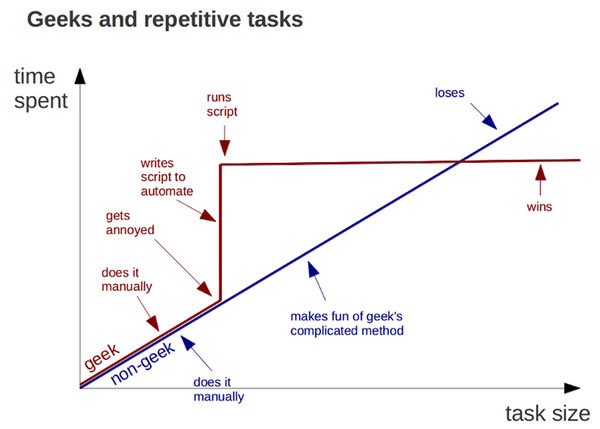 e comecei a imaginar algumas soluções.
e comecei a imaginar algumas soluções.
A URL tinha uma opçãozinha GET charmosa: &pAcIniNavprocessonomeadvselNav=1, então pensei: “dá pra fazer um script juntando wget e grep passando por todos os ‘pAcIniNavprocessonomeadvselNav’ pra achar essa parada”.
Na internet achei rapidamente a resposta:
~$ wget -q -O- "http://exemple.com" | grep -c palavra
Antes de fazer um loop qualquer fiz uns testes pra ver se era possível encontrar alguma coisa nessa página com essa técnica. Ainda apanhei um pouco antes de colocar as aspas pois em endereços simples não são necessárias.
Logo veio a graça da coisa. As linhas da tabela eram geradas por AJAX e o wget não “pegava” essa parte. Em qualquer outra parte da página, inclusive no cabeçalho da tabela o grep conseguia achar, mas as linhas da tabela eram geradas dinamicamente. Eu pensei então: “é só baixar todas as paginações dessa listagem e procurar nos arquivos HTML”.
Utilizando o plugin DownThemAll do firefox e o endereço da página com a listagem foi possível baixar mais ou menos 160 páginas HTML.
No DownThemAll é possível usar batch descriptors na URL, para baixar uma sequencia de páginas. Tem um exemplo no popup para adicionar o endereço para download, muito simples.
Quando eu adicionei a primeira vez, o DownThemAll me perguntou se eu realmente queria baixar 3600 páginas. Lembrei que tinha paginação da tabela, a cada 20 itens. O DownThemAll de forma inteligente aceita intervalos de iteração. Depois foi só colocar [1:3600:20] no local certo da URL para ele gerar os endereços e baixar as páginas HTML. Depois foi só rodar o grep na pasta:
~$ grep -r "Nome" .
para encontrar em qual arquivo existia o nome procurado.
Como o DownThemAll enumera automaticamente as páginas repetidas, foi só multiplicar o número do arquivo por 20 (da paginação) e ter o número da paginação na URL real. Ex.: arquivo 151*20 = 3020.
Finalmente foi possível encontrar todos os dados do processo na listagem do site.
No fim das contas acredito que perdi mais tempo escrevendo isso do que teria perdido procurando de forma braçal no site rs.
That’s all.